Fulbright 2019-2020 Research
The following are from the bitsvbytes website that I could salvage - while this project was put on hiatus during COVID, I learned a lot about designing public health interventions using a data-driven approach!
Selected Readings
The Mosquito: Timothy C. Winegard
Relevant Agencies
NEA: The National Environment Agency MOE: Ministry of Education HDB: Housing & Development Board MOH: Ministry of Health
Introduction
This page provides a comprehensive and current state of the project. Also see blog posts below tagged research and demos.
Phase 1: Planning
Until September 19th, I investigated potential leads to get data and information related to dengue spread in Singapore. I also tried out different technical leads like investigating new data processing techniques, packages, and datasets.
Phase 0: Proposal
This basic outline provides background for the scope and goals of this project.
“Our best defense is to eradicate mosquitoes and destroy breeding habitats, all over Singapore.”
Prime Minister Loong’s goals to address the mosquito-transmitted Zika virus are still relevant today (Baker, 2016). Despite investment in advanced technologies, like mosquito gene-editing, the most effective mosquito control technique is to eliminate stagnant water that mosquitoes breed in, like rain-filled ditches. Today, the Singapore National Environmental Agency (NEA) uses manually intensive methods to inspect urban areas for millions of mosquito breeding grounds due to Singapore’s tropical climate. This approach must be refined.
Singapore is a success story of urban planning at scale. This approach should be utilized in re-envisioning mosquito prevention strategies. Prof. Clayton Miller, head of the Building and Urban Data Science (BUDS) group at the National University of Singapore (NUS) combines urban design with data science. Their approach is similar to companies like Google, that use human-centered data science to revolutionize their products. The BUDS group investigates sustainable urban resource usage to improve quality of life by collecting and analyzing large environmental data sets from Internet-of-Things (IoT) sensors. IoT sensors are connected, modifiable devices which can transmit data remotely via the internet.
I propose an approach to mosquito control by combining my technical experience with BUDS’s human-centric urban data science methodology. I would implement the BUDS methodology by creating an IoT sensor network with a feedback loop, which I have named BuzzNET. The feedback loop of BuzzNet consists of analyzing sensor data (CO2, humidity, noise, temperature, etc.), suggesting and implementing mosquito control actions from that analysis, and then collecting more data to evaluate those actions. I will use IoT sensor data to determine environmental factors that allow mosquitoes to breed, like humidity near drains. Knowing that will guide me to recommend simple mosquito control actions, like unclogging the drain. These solutions will then be evaluated with new data analysis, like observing decreasing humidity readings. Using BuzzNET, we can determine factors that cause mosquito breeding grounds, and then suggest, implement, and evaluate mosquito control actions. BuzzNET demonstrates the feasibility of data science for mosquito control in urban design and opens the possibility of enormous benefit to human well-being globally.
Objective: The objective is to prototype an IoT sensor network with a feedback loop, BuzzNET, to detect and design against mosquito breeding grounds for Singaporean urban planners.
The project has four key phases:
Phase 1
Goal: Understand mosquito breeding grounds in Singapore by interviewing exterminators, the NEA, and residents about the environment, waste habits, and mosquito awareness.
Outcome: Find the optimal setting for 10 BuzzNETs
Phase 2
Goal: Setting up and testing the 10 sensor systems indoors and outdoors with suitable environmental protection.
Outcome: BuzzNETs are set-up.
Phase 3
Goal: Perform sensor upkeep, log human interaction data, and manually test for mosquito larvae counts. Simultaneously, use machine learning and computer vision techniques to quantify human interaction with the environment, determine breeding grounds (stagnant water breeding grounds are usually cooler than ambient air), and use data science to make environmental models of the breeding grounds.
Outcome: Identify environmental factors to be controlled to eliminate breeding grounds.
Phase 4
Goal: Use data models to recommend simple control actions in the urban environment, like unclogging drains. These would be evaluated using the Integrated Pest Model, where I would compare the mosquito counts, ambient environment, and impression of residents before and after the intervention. Finally, I will update the environmental models, thus completing the feedback loop.
Outcome: The models inform Singaporean urban planners about addressing and preventing mosquito breeding grounds.
Results: I will present NUS and NEA a BuzzNET prototype of data science applied to mosquito control. I will also write a report detailing my process and generalize it to IoT sensor feedback loops for other uses. The code and report will be public.
Detection Algorithms:
1. Object detection in Singapore:
Using Open Street Maps, I will select images from around Singapore and detect the prevalence of water-carrying objects. Today, an intern and I discussed what unexpected objects these may be. In Singapore, there are often mosquito breeding grounds where water pipes are leaking, in gutters, in parks, in potholes, and on roofs with uneven waterproofing. Some of these objects are not readily detected, leading to the second objective.
I started with downloading relevant environmental features from OpenStreetMaps, but found that Singapore is relatively un-annotated. OpenStreetMaps relies on human input to generate labels. I then used Geonames API. I processed that data and created a Blender model, displayed here as a gif and interactive model using Versa3D. Using Blender caused the most problems this week because Blender recently updated to a new format, breaking previous APIs.
2. Detection of Drainage Pipes
I have collected several images of drainage pipes in Singapore, and a Google search reveals several more. These drainage pipes are not easily identifiable, so I will need to train a model to detect these pipes.
3. Detection of Puddles
An existing (currently non-functional) model with provided weights claims to detect puddles on and off the road. I collected a small sample of puddles around Singapore during last week’s rain.
These first three objectives require some knowledge of computer vision, so I am going to finish an OpenCV tutorial and following along the relevant Youtube tutorials.
4. Preliminary Analysis of Datasets
After completing some excercises in QGIS, I will try my hand at basic statistical analysis for the existing mosquito datasets from the Singaporean government and add them to the demos page.
Sept 8, 2019
Demo 1 [Outdated]: Haze-NUS Application
A simple application that sends an alert when there are new haze conditions.
Demo 2 : Parks in Singapore
A simple representation of parks accross Singapore made in Blender.
Relevant Blogs
August 26, 2019
This week, we first solidified the project proposal. I will be building a mosquito model that takes in a variety of relevant sensor data, processes it, and outputs relevant suggestions to the user. I imagine it as a package that has applications where there are many sensors (like a building management system) or few to none (an app for a traveler). It should use global, local, real-time, and historical data.
There are four major parts to the project: Data: Global, local, direct, indirect data for mosquitoes Analysis: Different models and combining datasets Recommendations: Interviewing professionals Documentation: For ease of adaption and understanding
I’ve been looking and analyzing different readily available data sources. A promising existing technique is to use object recognition to determine risky areas for mosquitoes from images.
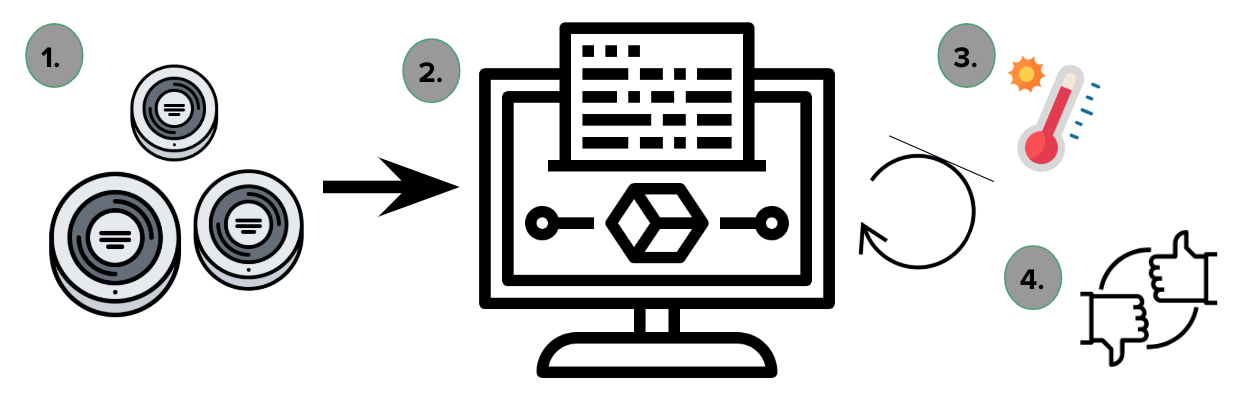
- Sensors gather data
- Model interprets data and produces a suggestion
- User implements Suggestion
- User provides feedback to the model
September 3, 2019
I experimented with Heroku, Weebly, Github pages, and CSS templates to build websites. So far, I’ve found that Github pages, for students, has the best value. You are able to keep the website repository private and still have a customizable website. The website template is Alembic (credits to David Darnes) and made in Jekyll. My favorite features are the integration with Github, the great customizability, and how it automatically rebuilds once a file is changed.
I preferred Github pages to Weebly for several reasons. First, Weebly costs money to add a custom domain. Second, it was difficult to get a professional look to the website. Finally, I would need to pay more money to remove the Weebly logo in the footer.
September 3 pt 2, 2019
This summer was good for mosquitoes and for articles about mosquitoes. I wanted to share some current cool research on mosquitoes from Singapore and abroad.
The Mosquito Laser While this strategy is extermination focused (not prevention focused), it incorporates non-chemical approaches. A laser detects mosquito movement and another laser kills the mosquito. This shows that mosquito movement is detectable and individual mosquitoes have distinct movements. This is also how animals identify mosquitoes - through their movement patterns.
Prevention as a Strategy Prevention of mosquitoes is the best strategy. While there is still discussion that mosquitoes are useless animals and can be exterminated, there are still many animals and ecosystems that depend on their presence. If prevention is possible in a non-invasive way, it would be ideal for humans.
Tactics in Singapore A quick browse through Singapore stores revealed the many Singaporeans rely on the government fogging to remove mosquitoes. The average Singaporean student is not overly concerned with encountering mosquitoes daily and does not wear bug spray. Two common household devices for mosquito control are bug lamps and sound repellents. Sound repellents are ineffective and bug lamps kill many beneficial bugs. The products sell, but the science behind them is still inconclusive.
Also, Geographic Information Science (GIS) is a critical tool in understanding mosquito populations in Singapore. The Singapore government updates data daily for mosquito counts and dengue cases in KML files. These files capture the mosquito counts and their location. GIS is integral for this project because preventing mosquitos means understanding their environment. I’m currently doing the GIS tutorial and learning geostatistics to apply to this project.
Computer Vision is an important tool because there are many picture-based datasets related to mosquitoes (like satellite images). An approach by Poom Wetttayakorn, analyzes images from Google Streetview for objects that commonly hold water, like buckets. Currently, this project is only for Thailand.
Another aspect where computer vision can help is in identifying common patterns in mosquito breeding areas. Humans are trained to identify mosquito breeding grounds by looking at a few factors:
- Undisturbed pools of Water
- Nearby Organic Matter
In the past week, I have identified some of these pools of water on my way to work. I can clearly tell where the mosquito breeding ground is. Can an algorithm detect the same?
The NEA takes pictures of every mosquito breeding ground. Image analysis of this data could yield interesting results.
Finally, there is an initiative to use drone images to find mosquitoes. If I can access these data sources, a computer vision approach could be powerful.
Update Oct 2nd:
One issue in my curated image processing set is the variance of colors. I recently found the color grade function from Adobe Grade. It can color match photos so that they look more uniform:
Notice how the third image has the colors of the second image and content of the first image. This is the power of color grading.
This technique may be able to help standardize my puddles dataset. As far as I see, current papers only discuss deep learning to enhance color grading, but do not discuss the impact of color grading on object detection or recognition. Could this be because colors themselves do not matter? What could be the impact on detecting reflective surfaces?
Update October 6th
A common error I get in vision models is : Kernel Died and restarting TF_XLA_FLAGS=–tf_xla_cpu_global_jit. This appears to be a setting in the operating systems itself.
September 7, 2019
Whenever I read a research paper proposing interesting results, I am happy when there is a link to the Github repository. I’ve found that research code is mostly unusable. I can’t figure out how to replicate the results, and there is no documentation to understand how to run the code.
For projects that are 2-3 years old, there are compatibility issues - broken links, defunct demos, deprecated software. Is it the responsibility of the researcher to provide useful code if they publish open source? Are they required to maintain this code after their project has completed?
I am guilty of poor open source practices, and now I am also feeling its bite. My hope is with better documentation, I can create easy-to-use modules that can easily be updated to match tomorrow’s technologies.
September 8, 2019
Whenever I read a research paper proposing interesting results, I am happy when there is a link to the Github repository. I’ve found that research code is mostly unusable. I can’t figure out how to replicate the results, and there is no documentation to understand how to run the code.
For projects that are 2-3 years old, there are compatibility issues - broken links, defunct demos, deprecated software. Is it the responsibility of the researcher to provide useful code if they publish open source? Are they required to maintain this code after their project has completed?
I am guilty of poor open source practices, and now I am also feeling its bite. My hope is with better documentation, I can create easy-to-use modules that can easily be updated to match tomorrow’s technologies.
September 15, 2019
For my project, I started with downloading relevant environmental features from OpenStreetMaps, but found that Singapore is relatively un-annotated. OpenStreetMaps relies on human input to generate labels. I then used Geonames API. I processed that data and created a Blender model, displayed here as a gif and interactive model using Versa3D. Using Blender caused the most problems this week because Blender recently updated to a new format, breaking previous APIs.
I added more pictures to the dataset of mosquito breeding grounds I was curating, and investigated a handful of relevant APIs. In my research, I ran into memory problems with AWS and the processing algorithms. The weights file with the existing puddles model has 5500 parameters and is quite large. I’m hoping this weekend I will make some progress.
September 25, 2019
On the 18th, I had the chance to connect with H3Zoom AI, a company that uses drones to inspect outdoor building surfaces. I hope that our discussion can help solidify how my project can help those in the industry make strides in mosquito control. Open collaboration with many users is essential to designing for public health.
That’s why on the 24th, I also visited the Urban Redevelopment Authority (URA) with an NUS trip. There, we saw the meticulous building planning for Singapore. Some historical decisions included leaving the Singapore river undammed, having more trees than people, and creating open planning projects for future generations in Singapore. These decisions show a commitment to sustainability and preservation.
Outside of research, some of my friends were worried that the haze would contaminate the rainwater. The URA guide mentioned that Singapore has several reservoirs and will probably not need to ration water for now. Still, the haze has been quite bad this week, so I have bought face masks to protect my nose. Because of this, sports training was at night. I was impressed by how many people play sports at night - the courts were packed! Finally, the ING competition day came, and I played touch rugby and soccer. While we did not win either sport, it was a lot of fun.
The most important thing this week was finishing and deploying the (now defunct in 2024) Haze App. It is now functional and has users. It was a challenge because many of the packages and tutorials were outdated. I hope to add additional functionality in the upcoming days!
September 30, 2019
I finally found out that my recurring charges from Amazon Web Services were from instances that were in different regions. Amazon only shows you the resources you are using from the current region in your dashboard. Finally, I’ve figured out why I’m being charged $0.18 monthly. I really could have used that spare change today. I left my windows open, so the rain ruined my air-drying clothes, and I’ll need to redo laundry.
October 6, 2019
When building and deploying the recent Heroku apps, I ran into trouble. The first was with database migrations. Often, the builds failed due to updates in how the database python packages operated together. In the free tier, Heroku App forces apps to sleep for some time every day, so Heroku Caffeine wakes up the application. Unfortunately, you can’t sign up for Heroku Caffiene right now, but hopefully it will be up soon. A final thought is the possibility of using AWS Beanstalk vs. Flask and Heroku vs. Pyramid for app building. Finally, adding an automated email to each person was challenging. I needed to change Gmail permissions and use the Gmail OAuth.
SAX, or Symbolic Aggregate Approximation, converts media so that it is easier to process. I’m still in the process of understanding. This summary was helpful to understand how converting time-series data to strings is useful. While much of the work was done in 2006, there seems to be recent work in 2019. I have time-series data on mosquitoes from the NEA portal. Perhaps I can use SAX to process this data.
- http://vigne.sh/posts/symbolic-aggregate-approximation/
- https://blogs.oracle.com/datascience/sax-and-matrix-profile-techniques-for-root-cause-analysis
- https://arxiv.org/abs/1905.00421
- https://cs.gmu.edu/~jessica/SAX_DAMI_preprint.pdf
- https://www.researchgate.net/post/How_does_the_symbolic_aggregate_approximation_SAX_technique_work
- https://jmotif.github.io/sax-vsm_site/morea/algorithm/SAX.html
So far I’ve heard three different reactions to mosquito control. Several people contracted dengue and described the pain of the disease. Others described the irritation, showed their mosquito bites, and bought mosquito preventative creams. A third group described the personal cost. Each breeding ground costs $100, so town halls get charged thousands of dollars due to the prevalence of these breeding grounds. All three are good reasons to keep persuing this topic.
I also learned that some people spay pressurized water at mosquito breeding grounds to clean the dirt, and they hope the aditional water will dry. And that roofs should be even and waterproofed, otherwise mosquitoes will breed. How can we use this information to keep Singapore safe from mosquitoes?
October 7, 2019
Today, I continued to work on the Telegram bot. I was able to deploy the bot using AWS API Gateway and AWS Lambda. I noticed that Telegram requests were processed out of order. Perhaps I need to use the MLQ package for job queuing. However, to access Google services, I have been unsuccessful in using Python because of Google Authentication. I am now trying GoLang, which appears to have only recently been made compatible with AWS.
I have not needed to use Java on any recent projects. While GoLang is still not universal, I opt to use it instead of Java whenever I can. Otherwise, I use Python because there are so many existing packages. I doubt that I will use Java at all during this research project.
Still, I have forgotten many parts of using Go. Unlike Python, you need to create and upload the GoLang executable to AWS Lambda. I also experimented with Adobe lightbox to enhance the puddles images before processing them.
October 9, 2019
I never thought I would use Google Photos when it first released in 2017. But now, two years later, I’m organizing my blog photos (and even research data) using Google Photos.
What inspired the change was finding a suitable medium to hold the puddles dataset. Google Photos could be shared easily, so I wanted to try it out. I combined the Telegram Chatbot and the Google Photos API tutorials to try creating a chatbot that displayed pictures from a specific album.
As previously discussed, I went through several failed tutorials and ultimately used this one. Currently, I can get photos locally using Python (not Go) and send photos via Telegram. I’m worried about the bill from AWS for all my failures, but I will address that later.
Right now, the challenge is to get AWS Lambda to recognize external packages in Python (import statements). Even when I include the modules from pip into the Lambda function, they do not load.
October 13, 2019
Today, I updated my shell to Fish upon my labmate’s recommendation. Fish is agile, clean, and even has a command autocomplete feature! As a result, I focused on creating useful executable shortcuts (like uploading blog posts without downloading the whole website). I planned to start with a simple task: creating a virtual environment in one command (instead of two). A virtual environment is like simulating a brand new computer for a new project. A key advantage is that leftover settings from a previous project won’t interfere in your virtual environment.
Before Fish, I needed two steps - create the virtual environment and then use the “source” command to activate it. Because I forgot the second command, I didn’t use virtual environments and had a series of mixed settings from a variety of unrelated projects. Now, when I may be sharing a computer with labmates projects, it is crucial to use virtual environments. After writing the code for step one in a few minutes, I thought creating an executable would take 15 minutes.
Four hours later, I had exhausted nearly every possible command to make “source” work. The main problem is that the source command is a builtin. That means it isn’t a separate executable waiting to be run. In BASH as well, there are a few familiar builtins, like “cd.” But In BASH, I can still call “bash -C cd ../” where the -C flag shows that the next argument can have builtins. But uniquely with Fish, there is no -C functionality! There is a temporary hack, but the maintainers said they would close the hack in the future.
Today’s work was a good revision of previous work in golang. But it was disappointing that I couldn’t externally call the builtin source command.
In other words, recreating the source command was a failure of sorts and a failure of source.
October 20, 2019
Today, we had a BUDS lab hackathon to explore Autodesk Forge. I plan to use Forge as a visualization tool that is like Verge 3D but has a lot more functionality and support. Today, I built a simple viewer with uploading files from a tutorial. Another interesting tutorial was building a 3D model from an image, which would be useful in terrain visualization. I plan to use satellite photos to test this functionality.
My overall goal is to modify these tutorials so that I can make interactive web visualizations for the website using pictures.
I also added more pictures to the puddles and drains dataset. This week, I will train new weights for the vision algorithms.
June 20, 2020
is a basketball simulation game that is challenging for even humans to master. It took me about an hour before I made my first point (mostly because I was using the wrong controls). So it’s no shock that reinforcement learning (RL) algorithms seem to have a tough time with this game. Now, not only am I new to reinforcement learning, but I am also new to Atari, and I have a lot to learn. However, in my initial forays into RL, I couldn’t help but notice that there was a lot more focus on mastering Montezuma’s Revenge, another Atari game, instead of a game like Double Dunk. Why Montezuma’s Revenge and not Double Dunk?
From gameplay, it’s clear that Montezuma’s Revenge and Double Dunk are two very different, challenging games. But from a learning algorithm standpoint, both games face some similar challenges. Both games have a large action space and sparse rewards, where the player must take multiple actions to reach a goal. Double Dunk appears more straightforward than Montezuma’s Revenge for one because the “map” of the game is smaller. I also believe that the rules for Double Dunk are a lot simpler than solving a puzzle maze in which humans require significant trial and error to beat. Double Dunk basketball, even without human knowledge of the game, appears to be a clear pattern of how to win the game and avoid opponents that can be learned.
Despite this, many algorithms perform poorly on both Double Dunk and Montezuma’s Revenge. One of the most popular papers on the topic, “Human-level control through deep reinforcement learning”, shows that Deep Q Networks, which typically outperform other algorithms on Atari games, perform worse on Double Dunk than other methods, and also performs worse than an average human tester. For Montezuma’s revenge, the methods perform way worse than humans.
Table from the “Human-level control paper”
| Game | Random | Linear | DQN | Human |
|---|---|---|---|---|
| Double Dunk | -18.6 | -13.1 | -18.1 | -15.5 |
| Montezuma’s Revenge | 0 | 10.7 | 0 | 4367 |
Yes, the performances between humans and the algorithm in Montezuma’s revenge are very different. But they’re also not good for Double Dunk. These results seem to mean that even humans were losing by 15 points. I find that hard to believe. Are humans this bad at playing Double Dunk? Does the score refer to something other than the points won from the game? Honestly, I don’t know because there are many variants of the game.
One reason Double Dunk could be more interesting than Montezuma’s revenge is that there are different termination conditions. One is running out of time, and the other a set number of points in the game. But there is no time limit on Montezuma’s revenge. Understanding the impact of the termination conditions could be an exciting direction for research to learn why we see algorithms performing the way they do. In general, I think categorizing the games among different dimensions and comparing their performances using various algorithms could give a lot more information about why some algorithms work and others don’t. I just haven’t found anything like this.
Since the DQN paper, advances to DQN’s and other reinforcement learning algorithms have been promising. Using the same algorithm and a distributed architecture, the researchers behind “Massively Parallel Methods for Deep Reinforcement Learning” showed the same DQN algorithm performing better than humans, but still losing the game. We also learn that the algorithm may not generalize well to states it hasn’t seen before. In another paper from Deep Mind, “Dueling Network Architectures for Deep Reinforcement Learning”, there is one algorithm that mostly scores positively for Double Dunk. Other papers also show the scores for Double Dunk as negative (such as this, this, and this) one. What’s going on? Surely, the game isn’t this difficult.
So maybe it makes sense why Montezuma’s Revenge became the focus of the RL community because it is undoubtedly a challenging game where many algorithms work uniformly awfully on. Still, there has to be a reason why we don’t yet see positive scores for Double Dunk. Perhaps there is merit in a case study of Double Dunk (or something that is not Montezuma’s Revenge). For example, there has been work specifically on “Space Invaders”. Could analyzing Double Dunk in a similar way be beneficial to the research community? There are plenty of YouTube videos that show humans playing Double Dunk successfully- is it even worth it to take the approach DeepMind used for Montezuma’s Revenge and use these videos? Maybe no one even cares about Double Dunk, which is why there is no current registered world record as there is for most Atari games. To even get a sense of how to answer these questions, I need to do some more reading, and more importantly, play some more games.
June, 2020
One resource we used in the BUDS lab is the Turing Way, a resource about the importance of open-source and reproducible research. The “Open Notebooks” was particularly important to me. Their principle of “make open what you can” is something I hope to emulate through this blog and through the work I do. Sure, my ideas can get scooped, but in the long term, if someone can benefit from an abandoned project or finds my current work interesting enough to collaborate, that is valuable. What I write will never be as perfect as I want it to be. But at some point, these imperfect ideas have more utility written openly than in my notebook. And looking back, I’ll be able to see how much I’ve learned about the research process as well.
An open-source checklist that was also pretty cool from the Turing Way.